RAG چیست و چرا از ChatGPT بهتر است؟ (به زبان ساده)
📌 خلاصه: RAG یک معماری هوشمند است که به مدلهای زبانی بزرگ مثل ChatGPT اجازه میدهد قبل از پاسخدهی، اسناد و اطلاعات اختصاصی سازمان شما را بخوانند. نتیجه؟ پاسخهای دقیقتر، شخصیسازیشده و با هالوسینیشن کمتر.
🔍 مقدمه: یک درد واقعی
تا به حال از ChatGPT درباره قوانین داخلی شرکتتان سؤال پرسیدهاید؟ احتمالاً یا جواب اشتباه داده، یا گفته به آن اطلاعات دسترسی ندارد.
این دقیقاً همان جایی است که RAG وارد میشود.
RAG باعث میشود هوش مصنوعی قبل از پاسخ دادن، اسناد و اطلاعات اختصاصی شرکت شما را بخواند و بعد جواب بدهد. به همین دلیل هم پاسخها دقیقتر میشوند و هم احتمال هالوسینیشن به شکل محسوسی کاهش پیدا میکند.
در این مقاله خیلی ساده توضیح میدهیم RAG چیست، چگونه کار میکند و چرا بسیاری از شرکتها به جای استفاده از ChatGPT خام، از RAG استفاده میکنند.
🤔 RAG چیست؟
RAG مخفف Retrieval-Augmented Generation است. در فارسی به آن «تولید تقویتشده با بازیابی» میگویند. اما این تعریف پیچیده را فراموش کنید. بیایید با یک مثال ساده بفهمیم:
💡 تصور کنید: ChatGPT مثل یک دانشجوی بسیار باهوش است که کتابهای زیادی خوانده، اما کتاب راهنمای شرکت شما را هرگز ندیده است.
RAG قبل از اینکه ChatGPT جواب بدهد، کتاب راهنمای شرکت را جلوی او باز میکند. سپس مدل بر اساس همان اطلاعات پاسخ میدهد.
به عبارت سادهتر، RAG یک پل ارتباطی بین هوش مصنوعی و اطلاعات اختصاصی شماست. این روش به مدل اجازه میدهد تا از دادههای داخلی سازمان استفاده کند، بدون اینکه نیاز به آموزش مجدد یا تغییر مدل اصلی باشد.
🧠 ChatGPT معمولی چگونه پاسخ میدهد؟
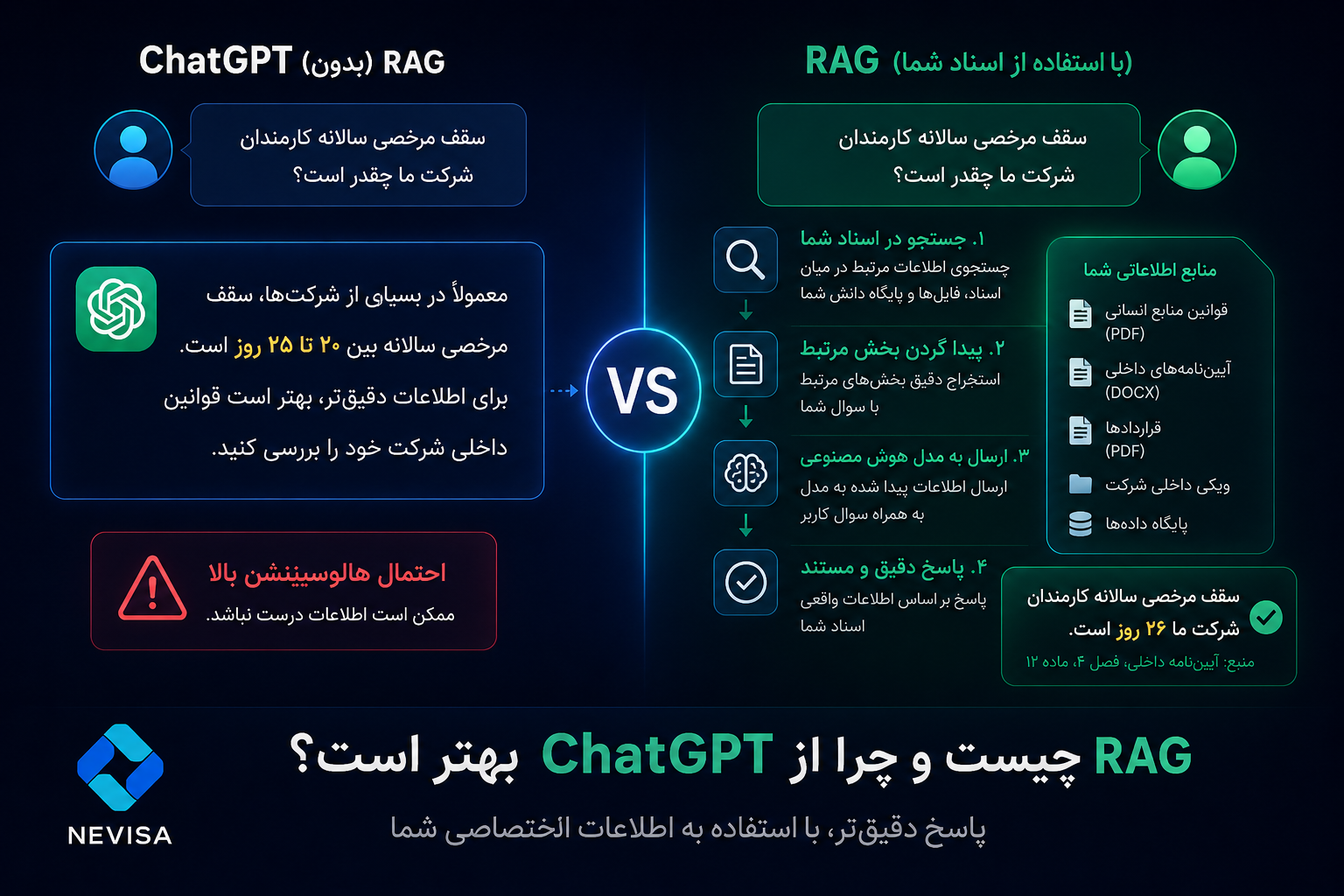
برای درک بهتر RAG، اول ببینیم ChatGPT معمولی (بدون RAG) چگونه کار میکند:
- ❌ فقط از دانشی که قبلاً آموزش دیده استفاده میکند.
- ❌ اطلاعات شرکت شما را نمیداند.
- ❌ ممکن است حدس بزند (و اشتباه کند).
- ❌ ممکن است هالوسینیشن داشته باشد (جوابی بدهد که کاملاً ساختگی است).
مشکل اصلی اینجاست که مدلهای عمومی مثل ChatGPT، روی دادههای عمومی آموزش دیدهاند. آنها هیچچیز دربارهی قوانین داخلی، محصولات خاص، قراردادها یا فرآیندهای سازمان شما نمیدانند. پس چطور میتوانند درست جواب دهند؟
⚙️ RAG چگونه کار میکند؟
فرآیند RAG را میتوان در ۵ مرحلهی ساده خلاصه کرد:
بیایید این مراحل را با جزئیات بیشتری توضیح دهیم:
مرحله ۱: سؤال کاربر
کاربر سوال خود را مطرح میکند. مثلاً: «سقف مرخصی سالانه کارمندان شرکت ما چقدر است؟»
مرحله ۲: جستجو داخل فایلها
سیستم RAG بلافاصله به پایگاه دادهی سازمان (که شامل فایلهای PDF، Word، Excel، ویکی داخلی، قوانین و...) مراجعه میکند.
مرحله ۳: پیدا کردن متن مرتبط
سیستم فقط بخشهایی از فایلها را که به سؤال کاربر مرتبط هستند، پیدا میکند. مثلاً بند مربوط به مرخصی در قوانین منابع انسانی را پیدا میکند.
مرحله ۴: ارسال متن به مدل
آن بخش از متن (مثلاً «سقف مرخصی سالانه ۲۶ روز است») به همراه سؤال اصلی، به مدل زبانی (مثل ChatGPT یا نویسا) ارسال میشود.
مرحله ۵: پاسخ نهایی
مدل بر اساس آن اطلاعات دقیق، پاسخ نهایی را تولید میکند.
📂 چرا RAG اطلاعات اختصاصی شرکت را میخواند؟
تصور کنید فایلهای زیر را به سیستم RAG بدهید:
- 📄 قوانین منابع انسانی
- 📄 قراردادها
- 📄 مستندات محصول
- 📄 ویکی داخلی
- 📄 فایلهای PDF
- 📄 دیتابیس
حالا وقتی کاربر سؤالی بپرسد، RAG فقط بخش مرتبط را پیدا میکند و به مدل میدهد.
نکته مهم: لازم نیست مدل دوباره آموزش ببیند! RAG این کار را بدون نیاز به آموزش مجدد (Fine-tuning) انجام میدهد. این یعنی در زمان و هزینهی شما صرفهجویی میشود.
🛡️ چرا RAG هالوسینیشن را کمتر میکند؟
هالوسینیشن (Hallucination) یعنی زمانی که هوش مصنوعی جوابی میدهد که کاملاً ساختگی است، اما با اعتماد کامل بیانش میکند. این یکی از بزرگترین چالشهای مدلهای زبانی است.
حالا بیایید با یک مثال مقایسه کنیم:
❌ ChatGPT معمولی:
سؤال: «سقف مرخصی کارمندان شرکت ما چقدر است؟»
ChatGPT نمیداند. پس یا میگوید: «معمولاً شرکتها ۲۰ روز...» یا یک عدد حدس میزند.
✅ RAG + ChatGPT:
سؤال: «سقف مرخصی کارمندان شرکت ما چقدر است؟»
RAG ابتدا فایل HR را باز میکند و میبیند نوشته شده: «سقف مرخصی سالانه ۲۶ روز است.»
سپس همان را پاسخ میدهد.
دلیل کاهش هالوسینیشن در RAG ساده است: مدل برای پاسخدهی، منبع معتبر در اختیار دارد. دیگر مجبور نیست حدس بزند یا از حافظهی عمومی خود استفاده کند.
📌 مثال واقعی: شرکت بیمه
بیایید یک سناریوی واقعی را تصور کنیم:
- 🏢 یک شرکت بیمه با ۵,۰۰۰ صفحه آییننامه و قوانین پیچیده.
- 👤 یک کارمند سؤال میپرسد: «آیا خسارت فلان مورد تحت پوشش بیمه است؟»
- 🔍 RAG در میان ۵,۰۰۰ صفحه، بخش مرتبط را پیدا میکند.
- 🤖 هوش مصنوعی همان بخش را میخواند و پاسخ دقیق را بر اساس آییننامه توضیح میدهد.
بدون RAG، کارمند باید ساعتها وقت بگذارد و خودش بین هزاران صفحه جستجو کند. اما با RAG، پاسخ در چند ثانیه و با دقت بالا دریافت میشود.
📊 آیا RAG همیشه بهتر از ChatGPT است؟
RAG در بسیاری از موارد برتری دارد، اما هر ابزاری جایگاه خودش را دارد. بیایید مقایسه کنیم:
| ویژگی | ChatGPT معمولی | RAG + ChatGPT |
|---|---|---|
| دانش عمومی | ✅ دارد | ✅ دارد |
| اطلاعات اختصاصی شرکت | ❌ ندارد | ✅ دارد |
| احتمال هالوسینیشن | 🟡 بیشتر | ✅ کمتر |
| شناخت فایلهای داخلی | ❌ نمیشناسد | ✅ میشناسد |
| نیاز به آموزش مجدد | ❌ ندارد | ✅ ندارد |
| پاسخها | 🟡 عمومی | ✅ شخصیسازیشده |
نتیجه: اگر به پاسخهای عمومی نیاز دارید، ChatGPT کافی است. اما اگر میخواهید هوش مصنوعی بر اساس اطلاعات اختصاصی سازمان شما پاسخ دهد، RAG انتخاب برتر است.
🏢 چه کسبوکارهایی به RAG نیاز دارند؟
تقریباً هر سازمانی که با دادههای اختصاصی و اسناد داخلی سروکار دارد، میتواند از RAG بهرهمند شود. از جمله:
- 🏢 شرکتهای نرمافزاری
- 🏥 بیمارستانها و مراکز درمانی
- 🏦 بانکها و مؤسسات مالی
- 🛍️ فروشگاههای آنلاین (ایکامرس)
- 🎓 دانشگاهها و مراکز آموزشی
- 🏛️ سازمانهای دولتی
- ⚖️ شرکتهای حقوقی
هر جایی که اسناد، قوانین، قراردادها یا پایگاه دانش وجود داشته باشد، RAG میتواند دسترسی به اطلاعات را سریعتر و دقیقتر کند.
❓ آیا RAG جای ChatGPT را میگیرد؟
خیر. RAG یک مدل هوش مصنوعی جدید نیست. بلکه روشی است که باعث میشود مدلهایی مثل ChatGPT، Gemini، Claude یا نویسا قبل از پاسخ دادن، اطلاعات اختصاصی شما را هم مطالعه کنند.
در واقع RAG یک لایهی اضافی است که روی مدلهای زبانی سوار میشود و آنها را برای استفادهی سازمانی آماده میکند.
🔚 جمعبندی
RAG یک تحول اساسی در نحوهی تعامل سازمانها با هوش مصنوعی است. این روش به مدلهای زبانی اجازه میدهد تا از اطلاعات اختصاصی شرکت استفاده کنند، پاسخهای دقیقتری بدهند و هالوسینیشن را به حداقل برسانند. همهی اینها بدون نیاز به آموزش مجدد مدل و صرف هزینههای سنگین.
💡 و اینجا نویسا وارد میشود:
اگر قصد دارید یک چتبات سازمانی بسازید که بتواند فایلهای PDF، Word، Excel، مستندات داخلی یا پایگاه دانش شرکت شما را بخواند و بر اساس آنها پاسخ دهد، استفاده از معماری RAG یکی از بهترین گزینههاست.
نویسا نیز از این معماری برای ایجاد دستیارهای هوشمند مبتنی بر اطلاعات اختصاصی سازمانها پشتیبانی میکند.
اگر میخواهید بیشتر درباره قابلیتهای نویسا بدانید، راهنمای جامع استفاده از نویسا را مطالعه کنید. همچنین میتوانید همین حالا ثبتنام کنید و نویسا را بهصورت رایگان تست کنید.
❓ سوالات متداول
❓ RAG مخفف چیست؟
RAG مخفف Retrieval-Augmented Generation است که به معنای «تولید تقویتشده با بازیابی» میباشد.
❓ آیا RAG یک مدل هوش مصنوعی است؟
خیر. RAG یک معماری یا روش است که روی مدلهای زبانی سوار میشود تا بتوانند از اطلاعات خارجی استفاده کنند.
❓ تفاوت RAG و Fine-tuning چیست؟
Fine-tuning یعنی آموزش مجدد مدل روی دادههای جدید که هزینهبر و زمانبر است. اما RAG بدون نیاز به آموزش مجدد، اطلاعات جدید را در لحظه به مدل میدهد.
❓ آیا RAG بدون اینترنت هم کار میکند؟
بله. اگر فایلها و پایگاه دادهی شما بهصورت لوکال (محلی) ذخیره شده باشد، RAG میتواند بدون نیاز به اینترنت کار کند.
❓ آیا RAG فقط برای ChatGPT است؟
خیر. RAG را میتوان روی هر مدل زبانی (GPT، Gemini، Claude، نویسا و...) پیادهسازی کرد.
❓ آیا RAG هالوسینیشن را کاملاً حذف میکند؟
کاملاً خیر، اما به شکل قابل توجهی آن را کاهش میدهد. اگر اطلاعات موجود در پایگاه داده ناقص یا اشتباه باشد، ممکن است پاسخ همچنان اشتباه باشد.
❓ چه فایلهایی را میتوان به RAG داد؟
فایلهای PDF، Word، Excel، PowerPoint، ویکی داخلی، دیتابیس، ایمیلها و هر منبع دادهی متنی دیگر.
❓ آیا برای استفاده از RAG باید مدل را دوباره آموزش داد؟
خیر. این بزرگترین مزیت RAG است. نیازی به آموزش مجدد (Fine-tuning) نیست و مدل بلافاصله پس از اتصال به پایگاه داده، از اطلاعات جدید استفاده میکند.


